转自: https://www.cnblogs.com/zhaopei/p/4189583.html
阅读目录 功能一:备份博客到本地 1.加载推荐博客 2.加载随笔分类、档案和标签 3.点击备份 功能二:浏览本地博客 1.递归加载目录下所以博客文件 2.点击加载博客内容(这里使用到了webBrowser控件来... 功能三:本地浏览关键字搜索 1.首先在备份的时候就需要创建搜索索引。 2.点击搜索 下载地址: 接着 博客转发小工具2 ,又弄了一个第三版。主要功能有:博客备份到本地、浏览备份到本地的博客、关键字搜索本地的博客和转发博客可以选择个人分类 填写Tag标签。其实想了想,转发博客干嘛非要在本地客户端转发,直接在博客园的页面用js不就可以达到目的么。想是这么想,还没尝试。等我写完了这个博客就去试试。。继续回到这个小工具,说实在的本人做的这个小工具界面丑的那是、、反正就是很丑很丑啦。没办法,没有美工的那种艺术细胞。还有就是,整个功能其实真没什么技术含量,还是html的抓取,winfrom在工作中也没用过,就平时偶尔玩玩,望大神们勿喷~~。
不过我觉得这个小工具的作用:第一、可以用来备注自己的博客,自己留个底。第二、某些朋友的工作环境可能没有外网(我以前的公司就没有),这样的话可以用来备份一些博友的系类文章当资料。【要是可以的话,把系类文章导成dpf文档那就更爽了。可是我一直没成功~】。
也许有写人会说:啥啥啥的早就有类似的软件了。我不知道,我没用过,我觉得自己做的用着开心。就当练手吧。开始说内容了。
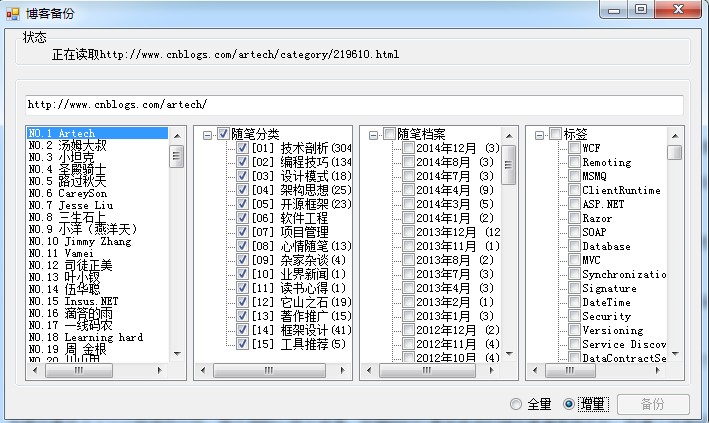
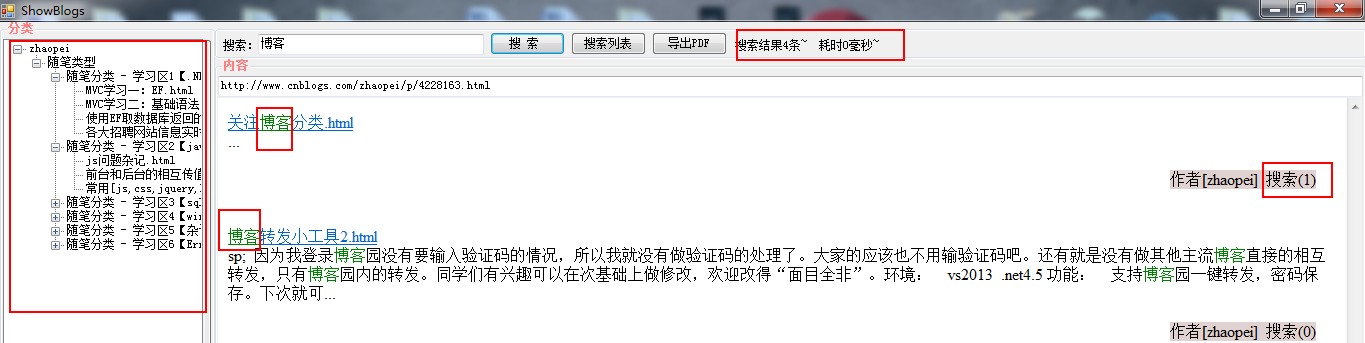
功能一:备份博客到本地
备份的博客是博客园推荐的前150个。也可以自己手动输入要备份的url。
1.加载推荐博客
var docment = new HtmlAgilityPack.HtmlDocument();
docment.LoadHtml(BlogCommon.PostReqest(BlogUrlString.推荐博客url));
var nodes = docment.DocumentNode.SelectNodes("//ul//a");
List<object> list = new List<object>();
for (int i = 0; i < nodes.Count; i++)
{
var url = "http://www.cnblogs.com" + nodes[i].Attributes["href"].Value;
var name = "NO." + (i + 1).ToString() + " " + nodes[i].InnerText;
list.Add(new { url = url, name = name });
}
list_tuijian.DataSource = list;
list_tuijian.ValueMember = "url";
list_tuijian.DisplayMember = "name";2.加载随笔分类、档案和标签 首先选中博客改变url,然后url文本框的TextChanged事件里面加载 随笔分类、档案和标签数据。
var docment = new HtmlAgilityPack.HtmlDocument();
docment.LoadHtml(BlogCommon.GetRequest(BlogUrlString.个人博客分类url(strname)));
//加载随笔类型
LoadTree(docment, "//div[@class='catListPostCategory']//a", tree_suibiType, "随笔分类");
tree_suibiType.CheckBoxes = true;
// 加载随笔档案
LoadTree(docment, "//div[@class='catListPostArchive']//a", tree_suibiTime, "随笔档案");
tree_suibiTime.CheckBoxes = true;
//// 加载文章类型
//LoadTree(docment, "//div[@class='catListArticleCategory']//a", tree_wenzhangType, "文章类型");
//tree_suibiType.CheckBoxes = true;
docment.LoadHtml(BlogCommon.GetRequest(BlogUrlString.标签url(strname)));
// 加载文章类型
LoadTree(docment, "//div[@id='taglist']//a", tree_tag, "标签");
tree_tag.CheckBoxes = true;public void LoadTree(HtmlAgilityPack.HtmlDocument docment, string where, TreeView trre, string TreeName)
{
try
{
trre.Nodes.Clear();
var nodes = docment.DocumentNode.SelectNodes(where);
if (nodes == null || nodes.Count <= 0)
return;
List<object> list = new List<object>();
TreeNode treenodeS = new TreeNode() { Name = "", Text = TreeName };
for (int i = 0; i < nodes.Count; i++)
{
TreeNode treenode = new TreeNode();
var url = nodes[i].Attributes["href"].Value;
var name = nodes[i].InnerText;
list.Add(new { url = url, name = name });
treenode.Text = name;
treenode.Name = url;
treenodeS.Nodes.Add(treenode);
}
trre.Nodes.Add(treenodeS);
trre.ExpandAll();//展开节点
}
catch (Exception ex)
{
MessageBox.Show("加载" + TreeName + "错误" + ex.Message);
}
}3.点击备份 点击备份,读取选中的复选框所包含的所有url。
#region 获取某个选中树节点 的所有url地址
public List<string[]> getShuibiType_all_url(string url, ref List<string[]> list_urlS)
{
label1.Text = "正在读取" + url;
var docment = new HtmlAgilityPack.HtmlDocument();
docment.LoadHtml(BlogCommon.GetRequest(url));
// a class entrylistItemTitle entrylistTitle
var nodes = docment.DocumentNode.SelectNodes("//div[@class='entrylist']//div[@class='entrylistPosttitle']//a");
if (nodes == null)
nodes = docment.DocumentNode.SelectNodes("//div[@id='content']//div[@class='post post-list-item']/h2/a");
var entrylistTitle = docment.DocumentNode.SelectNodes("//h1[@class='entrylistTitle']");
if (entrylistTitle == null)
entrylistTitle = docment.DocumentNode.SelectNodes("//div[@id='content']/h2");
var posts_title = entrylistTitle != null ? entrylistTitle[0].InnerText : "未分类";
if (nodes != null && nodes.Count > 0)
{
for (int j = 0; j < nodes.Count; j++)
{
label1.Text = "正在读取[" + posts_title + "]" + (j + 1) + "/" + nodes.Count + "页" + "url地址";
list_urlS.Add(
new string[]
{
nodes[j].Attributes["href"].Value,
nodes[j].InnerText,
entrylistTitle.Count>=1?entrylistTitle[0].InnerText:"未分类"
});
}
}
return list_urlS;
}
#endregion点击备份,保存到本地。
#region 保存内容到文件
/// <summary>
/// 保存内容到文件
/// </summary>
/// <param name="list_str">根据地址集合</param>
/// <param name="type"></param>
/// <param name="docment"></param>
public void SaveFile(List<string[]> list_str, string type, HtmlAgilityPack.HtmlDocument docment)
{
if (list_str == null || list_str.Count <= 0)
return;
for (int i = 0; i < list_str.Count; i++)
{
var url = list_str[i][0];
var name = url.Split('/').Length >= 4 ? url.Split('/')[3] : "未分类";
if (list_str[i].Length == 3)
{
try
{
label1.Text = "正在请求[" + name + "/" + type + "]页面" + (i + 1) + "/" + list_str.Count + "。";
#region 文件路径处理
//过滤文件名的特殊字符
string[] rep = new string[] { "—", ":", "<", ">", "?", "*", "/", "|", "\"" };
string fileNmae = list_str[i][1].Replace("\\", string.Empty);
for (int j = 0; j < rep.Length; j++)
{
if (rep[j].Length == 0)
continue;
fileNmae = fileNmae.Replace(rep[j], string.Empty);
}
var Paht = ForwardPath + name + "\\" + type + "\\" + list_str[i][2] + "\\";
for (int j = 0; j < rep.Length; j++)
{
if (rep[j].Length == 0)
continue;
Paht = Paht.Replace(rep[j], string.Empty);
}
Paht = FileHelp.PathBlogs + Paht;
var FilePath = Paht + fileNmae + ".html";
#endregion
if (radioButton2.Checked && File.Exists(FilePath))
{
label1.Text = "页面数据存在[" + name + "/" + type + "]页面" + (i + 1) + "/" + list_str.Count + "。";
continue;
}
var html = BlogCommon.GetRequest(url);
docment.LoadHtml(html);
var Nodes = docment.DocumentNode.SelectNodes("//div[@class='postBody']");
if (Nodes == null)
Nodes = docment.DocumentNode.SelectNodes("//div[@id='cnblogs_post_body']");
html = Nodes[0].InnerHtml;
docment.DocumentNode.InnerHtml = "<div id='my_html_postBody'>" + html + "</div>";
#region 去掉a标签的超链接
//去掉a标签的超链接
var html_aS = docment.DocumentNode.SelectNodes("//a");
if (html_aS != null)
for (int z = 0; z < html_aS.Count; z++)
if (html_aS[z].Attributes["href"] != null && html_aS[z].Attributes["href"].Value[0] != '#')
html_aS[z].Attributes["href"].Value = "javascript:void()";
#endregion
label1.Text = "准备保存[" + name + "/" + type + "]内容" + (i + 1) + "/" + list_str.Count + "~";
FileHelp.CreatePath(Paht + @"imgs\");
saveImg(docment, Paht + @"imgs\", label1.Text + "...");
docment.CreateAttribute("url", url);
//profile_block
docment.DocumentNode.InnerHtml = "<div id='mytext_url'>" + url + "</div>"
+ "<div id='mytext_BlogTitleName'>" + name + "</div>"
+ docment.DocumentNode.InnerHtml;
docment.Save(FilePath, Encoding.UTF8);
File.SetCreationTime(FilePath, new DateTime(FileHelp.Ticks));
LuceneHelp.CreateIndexFilePath(FilePath);
//FileHelps.SaveFile(Paht, fileNmae + ".txt", html);
label1.Text = "保存成功" + (i + 1) + "/" + list_str.Count + "。";
}
catch (Exception ex)
{
string mess = url + "\r\n" + ex.Message + "\r\n" + ex.StackTrace + "\r\n\r\n";
string myPath = FileHelp.PathBlogs + ForwardPath + name + "\\" + type + "\\";
FileHelp.SaveFile(myPath, "err.txt", mess, false);
}
}
else
FileHelp.SaveFile(FileHelp.PathBlogs + ForwardPath + name + "\\" + type + "\\", "err.txt", "异常373位置", false);
}
}
#endregion功能二:浏览本地博客
1.递归加载目录下所以博客文件 (这个方法不行,如果文件多的话,会有点卡。以后要改成点击加载下层目录)
public TreeNodeCollection loadTree(string path, TreeNodeCollection treeS, bool isNe = true)
{
List<string[]> list = FileHelp.FileSystemInfo(path, "3");
string[] str = new string[] { "", "" };
if (list != null)
{
for (int i = 0, j = 0; i < list.Count; i++, j++)
{
if (list[i][0] == "imgs")
{
j--;
continue;
}
TreeNode tree1 = new TreeNode() { Text = list[i][0] };
treeS.Add(tree1);
loadTree(list[i][1], treeS[j].Nodes);
}
}
return treeS;
}2.点击加载博客内容(这里使用到了webBrowser控件来显示博客内容)
#region 点击tree树 加载对应内容
/// <summary>
/// 点击tree树 加载对应内容
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void treeView1_AfterSelect(object sender, TreeViewEventArgs e)
{
if (e.Action == TreeViewAction.ByMouse || e.Action == TreeViewAction.ByKeyboard)
{
htmlPath = FileHelp.PathBlogs + Forward.ForwardPath + e.Node.FullPath;
string html = FileHelp.GetFile(htmlPath);
HtmlAgilityPack.HtmlDocument docment = new HtmlAgilityPack.HtmlDocument();
docment.LoadHtml(html);
try
{
var text_html = docment.DocumentNode.SelectNodes("//div[@id='my_html_postBody']")[0].InnerHtml;
var mytext_url = docment.DocumentNode.SelectNodes("//div[@id='mytext_url']")[0].InnerHtml;
webBrowser1.DocumentText = text_html;
text_url.Text = mytext_url;
}
catch (Exception)
{ }
}
}
#endregion功能三:本地浏览关键字搜索
搜索使用的Lucenne.net。这里面的水太深了。这里就使用到了点皮毛。这里给出一些资料地址。
1.首先在备份的时候就需要创建搜索索引。
/// <summary>
/// 创建索引
/// </summary>
/// <param name="analyzer"></param>
/// <param name="title"></param>
/// <param name="content"></param>
private static void AddIndex(IndexWriter writer, string title, string content, string filePath, string id, string mytext_BlogTitleName = "Blog", string ClickQuantity = "0")
{
try
{
// Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS));
Document doc = new Document();
doc.Add(new Field("Title", title, Field.Store.YES, Field.Index.ANALYZED));//存储且索引
//doc.Add(new Field("Content", content, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS));// Field.Store.YES, Field.Index.ANALYZED));//存储且索引
doc.Add(new Field("Content", content, Field.Store.YES, Field.Index.ANALYZED));
doc.Add(new Field("filePath", filePath, Field.Store.YES, Field.Index.NOT_ANALYZED));//存储且索引
doc.Add(new Field("BlogTitleName", mytext_BlogTitleName, Field.Store.YES, Field.Index.NOT_ANALYZED));
doc.Add(new Field("id", id, Field.Store.YES, Field.Index.NOT_ANALYZED));
doc.Add(new Field("ClickQuantity", ClickQuantity, Field.Store.YES, Field.Index.NOT_ANALYZED));
//防止重复索引
writer.DeleteDocuments(new Term("id", id));
//AddTime
writer.AddDocument(doc);
}
catch (FileNotFoundException fnfe)
{
throw fnfe;
}
catch (Exception ex)
{
throw ex;
}
}2.点击搜索
#region 点击搜索
private void but_select_Click(object sender, EventArgs e)
{
new Thread(delegate()
{
try
{
lab_meg.Text = "正在搜索.....";
var htm = "";
var list = LuceneHelp.SelectData(FileHelp.PathBlogs + "Index\\", txt_select.Text.Trim(), this.lab_meg);
var count = 150;
if (list.Count >= count)
{
var mess = MessageBox.Show("搜索结果过多,是否只显示前" + count + "条~", "提示", MessageBoxButtons.YesNo, MessageBoxIcon.Asterisk);
if (mess == System.Windows.Forms.DialogResult.Yes)
{
int index = 0;
foreach (var item in list)
{
index++;
htm += "<a name='click_load_file' href='#' filePath='" + item.FilePath + "'>" +
item.FileName + "</a><br/><div>" + item.Content
+ "<div><br/><div style='width:100%;text-align:right;'><span style='margin-right:20px;background-color:#e1d2d2'>作者["
+ item.BlogTitleName + "] 搜索(" + item.ClickQuantity + ")</span></div><br/><br/>";
if (index >= count)
break;
}
}
else
foreach (var item in list)
{
htm += "<a name='click_load_file' href='#' filePath='" + item.FilePath + "'>" +
item.FileName + "</a><br/><div>" + item.Content
+ "<div><br/><div style='width:100%;text-align:right;'><span style='margin-right:20px;background-color:#e1d2d2'>作者["
+ item.BlogTitleName + "] 搜索(" + item.ClickQuantity + ")</span></div><br/><br/>";
}
}
else
{
foreach (var item in list)
{
htm += "<a name='click_load_file' href='#' filePath='" + item.FilePath + "'>" +
item.FileName + "</a><br/><div>" + item.Content
+ "<div><br/><div style='width:100%;text-align:right;'><span style='margin-right:20px;background-color:#e1d2d2'>作者["
+ item.BlogTitleName + "] 搜索(" + item.ClickQuantity + ")</span></div><br/><br/>";
}
}
webBrowser1.DocumentText = htm;
htmlList = htm;
}
catch (Exception ex)
{
//MessageBox.Show(ex.Message);
lab_meg.Text = "搜索出错~" + ex.Message;
}
}).Start();
}
#endregion下载地址:
环境:vs2013 版本:.Net Framework4.5 数据库:无
程序下载 源码下载 (源码都给您了,顺手点个赞呗~~)
