mobilenet 介绍
目标检测
目标检测算法使用已知的对象类别集合来识别和定位图像中的对象的所有实例。该算法接受图像作为输入并输出对象所属的类别,以及它属于该类别的置信度分数,该算法还使用矩形边界框预测对象的位置和比例。
目标检测的目的是“识别对象并给出其在图中的确切位置”,可以分为三部分:
- 识别某个对象
- 给出对象在图中的位置
- 识别图中所有的目标及其位置
滑动窗口
滑动窗口法是进行目标检测的主流方法,对于某输入图像,由于其对象尺度形状等因素的不确定性,导致直接套用预训练好的模型进行识别效率地下。通过设计滑窗来遍历图像,对每个滑窗对应的局部图像进行检测,能有效克服尺度、位置、形变等带来的输入问题,提升检测效果。
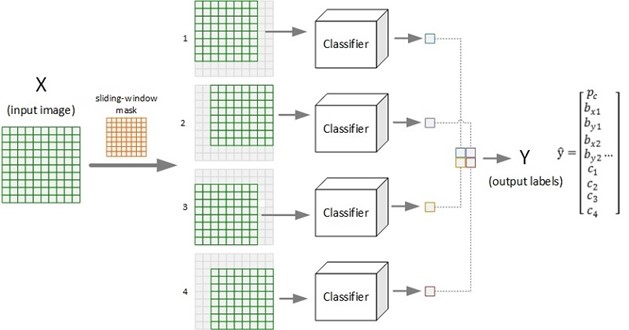
展示采用滑窗(尺寸 = 8 8, 步进 = 2)对图片(10 10)进行对象检测的过程示意。图示的输出为 2 * 2 的网格,每个格子对应一个输出标签向量,给出了原图对应的窗口区域图像的检测结果(置信度、边框位置、各类别概率等)。
mobilenet
要实现目标检测,需要有相应的目标识别模型(Classifier),卷积神经网络(CNN)是其中的主流模型之一。但是这样的网络架构非常大,需要的算力太大,不适合部署在边缘设备上。Google 在 2017 年提出了适用于移动设备上的轻量级神经网络 MobileNets,专为资源受限的边缘设备而设计。
MobileNets 与传统 CNN 的区别,主要使用了深度可分离卷积 Depthwise Separable Convolution 将卷积核进行分解计算来减少计算量。深度可分离卷积就是将普通卷积拆分成为一个深度卷积和一个逐点卷积。
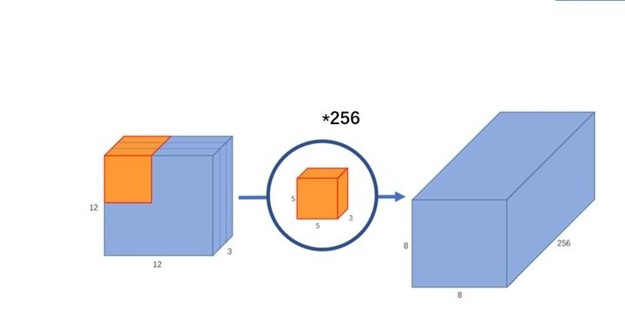
标准卷积:假设输入一个 12 12 3 的一个输入特征图,经过 5 5 3 的卷积核卷积得到一个 8 8 1 的输出特征图;如果此时我们有 256 个特征图,我们将会得到一个 8 8 256 的输出特征图。如下
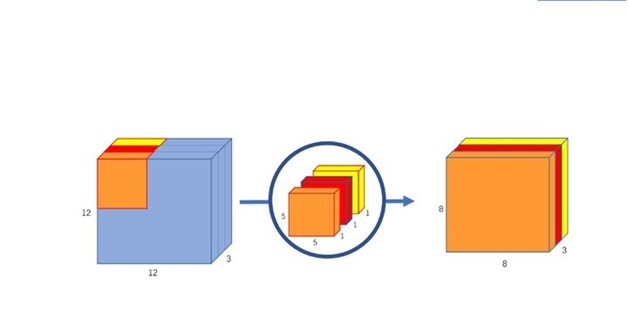
深度卷积:我们将卷积核拆分成为单通道形式,在不改变输入特征图像的深度情况下,对每一通道进行卷积操作,这样就得到了核输入特征图通道数一致的输出特征图。假设输入 12 12 3 的特征图,经过 5 5 1 3 的深度卷积之后,得到了 8 8 * 3 的输出特征图,如下图。输入和输出的维度一致都是3,这样就会有一个问题,通道数太少,特征图维度太少,有效信息过少。
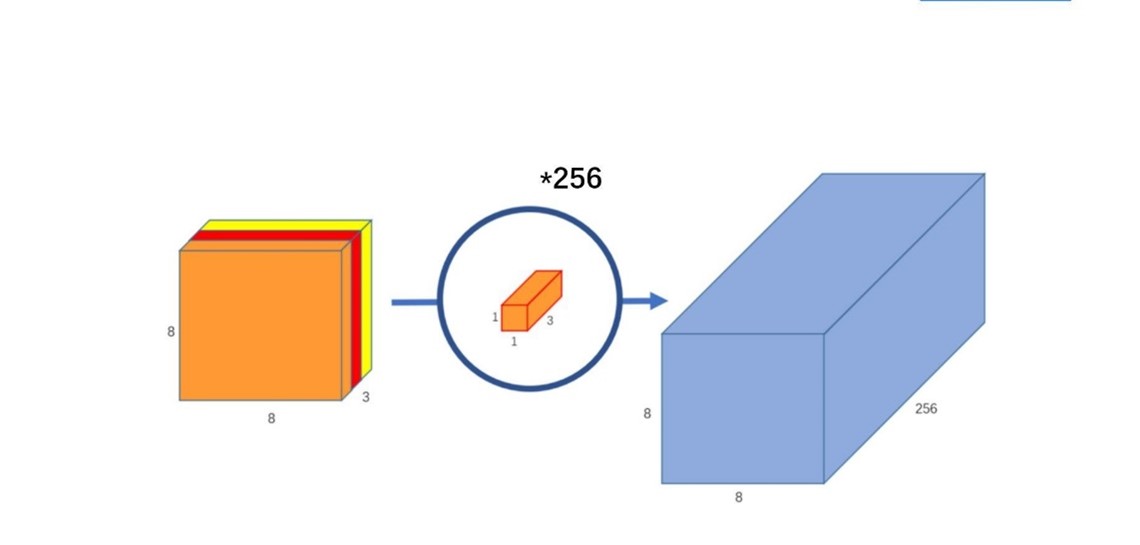
逐点卷积:1 1 卷积,主要作用是对特征图进行升维和降维,如下图。在深度卷积的过程中,我们得到了 8 8 3 的输出特征图,我们用 256 个 1 1 3 的卷积核对输入特征图进行卷积操作,输出的特征图就和标准的卷积操作一样都是 8 8 * 256 了。
标准卷积与深度可分离卷积的过程对比如下
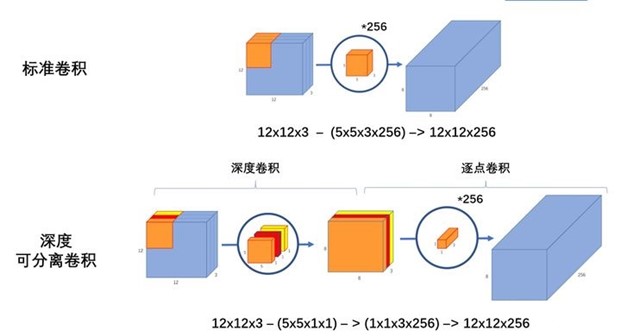
深度可分离卷积可以用更少的参数,更少的运算,得到差不多的结果。卷积核的尺寸是 Dk Dk M,某层卷积输入的尺寸是 Dw Dh N 的特征图,那么标准卷积的运算量是:Dk Dk M N Dw Dh;而深度可分离卷积的运算量是:Dk Dk M Dw Dh + M N Dw Dh。我们通常使用的是 3 * 3 的卷积核,通过深度可分离卷积可以让运算量下降到标准卷积的九分之一左右。
SSD 介绍
SSD采用VGG16作为基础模型,并且做了以下修改,如图所示
- 分别将VGG16的全连接层FC6和FC7转换成 3x3 的卷积层 Conv6和 1x1 的卷积层Conv7
- 去掉所有的Dropout层和FC8层
- 同时将池化层pool5由原来的 stride=2 的 2x2 变成stride=1的 3x3
- 添加了Atrous算法(hole算法),目的获得更加密集的得分映射
- 然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测

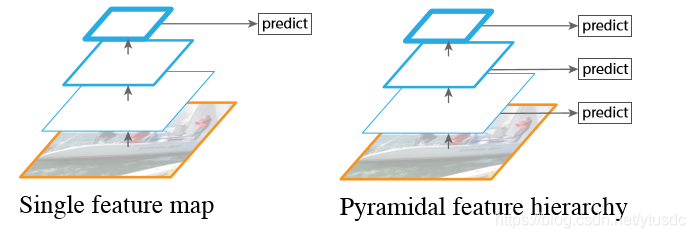
左边的方法针对输入的图片获取不同尺度的特征映射,但是在预测阶段仅仅使用了最后一层的特征映射;而SSD(右图)不仅获得不同尺度的特征映射,同时在不同的特征映射上面进行预测,它在增加运算量的同时可能会提高检测的精度,因为它具有更多的可能性。
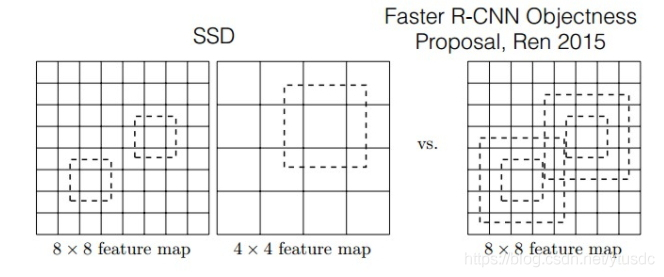
对于BB(bounding boxes)的生成,Faster-rcnn和SSD有不同的策略,但是都是为了同一个目的,产生不同尺度,不同形状的BB,用来检测物体。对于Faster-rcnn而言,其在特定层的Feature map上面的每一点生成9个预定义好的BB,然后进行回归和分类操作来进行初步检测,然后进行ROI Pooling和检测获得相应的BB;而SSD则在不同的特征层的feature map上的每个点同时获取6个(有的层是4个)不同的BB,然后将这些BB结合起来,最后经过NMS处理获得最后的BB。
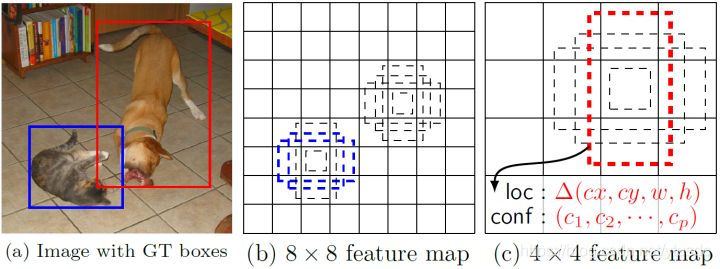
图片被送进网络之后先生成一系列 feature map,传统框架会在 feature map(或者原图)上进行 region proposal 提取出可能有物体的部分然后进行分类,这一步可能非常费时,所以 SSD 就放弃了 region proposal,而选择直接生成一系列 defaul box,然后以prior box 为初始bbox,将bboxes回归到正确的GT位置上去,预测出的定位信息实际上是回归后的bboxes和回归前的(prior box)的相对坐标。整个过程通过网络的一次前向传播就可以完成。
NMS(非极大值抑制)
在SSD算法中,NMS至关重要,因为多个feature map 最后会产生大量的BB,然而在这些BB中存在着大量的错误的、重叠的、不准确的BB,这不仅造成了巨大的计算量,如果处理不好会影响算法的性能。仅仅依赖于IOU(即预测的BB和GT的BB之间的重合率)是不现实的,IOU值设置的太大,可能就会丢失一部分检测的目标,即会出现大量的漏检情况;IOU值设置的太小,则会出现大量的重叠检测,会大大影响检测器的性能,因此IOU的选取也是一个经验活,常用的是0.65,建议使用论文中作者使用的IOU值,因为这些值一般都是最优值。即在IOU处理掉大部分的BB之后,仍然会存在大量的错误的、重叠的、不准确的BB,这就需要NMS进行迭代优化。
SSD 优劣
SSD算法的优点应该很明显:运行速度可以和YOLO媲美,检测精度可以和Faster RCNN媲美。SSD对不同横纵比的object的检测都有效,这是因为算法对于每个feature map cell都使用多种横纵比的default boxes。
缺点是:需要人工设置很多参数值,调试过程非常依赖经验。对小目标的recall依然一般,并没有达到碾压Faster RCNN的级别。
tengine 框架和 api
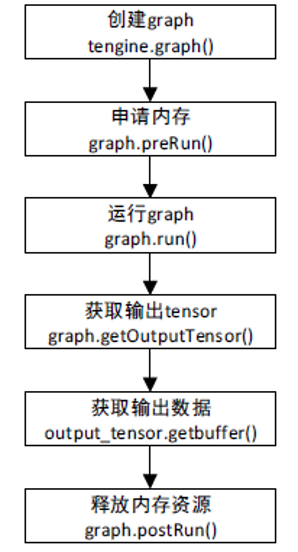
api
加载 tengine 库
os.environ['LD_LIBRARY_PATH'] = '../Tengine-lite/lib/aarch64'
from tengine import tg生成 graph
class Graph(object):
def __init__(self, context=None, model=None, *kwarg):获得输入 tensor
def getInputTensor(self, nodeidx, idx):设置输入维度
dims = [1, 3, height, width]
inputTensor.shape = dims为 graph 执行准备资源
def preRun(self):配置输入数据
inputTensor.buf = data执行推理,0是非阻塞,1是阻塞
def run(self, block=0):获取输出 tensor
def getOutputTensor(self, nodeidx, idx):获取输出数据
outputTensor.buf参考
https://zhuanlan.zhihu.com/p/70703846
https://zhuanlan.zhihu.com/p/33544892
https://blog.csdn.net/ytusdc/article/details/86577939
https://github.com/OAID/Tengine/tree/fcf2da5a14bd26a43d5fe09cb577caac3ecd3b3c/examples
