主要方法
-
基于知识的检测方法:检测器官特征和器官之间的几何关系。主要利用先验知识将人脸看作器官特征的组合,根据眼睛、眉毛、嘴巴、鼻子等器官的特征以及相互之间的几何位置关系来检测人脸。 主要的检测方法:模板匹配,人脸特征,形状与边缘,纹理特征,颜色特征。
- 基于统计的检测方法:像素相似性度量。将人脸看作一个整体的模式——二维像素矩阵,从统计的观点通过大量人脸图像样本构造人脸模式空间,根据相似度量来判断人脸是否存在。 主要的检测方法:成分分析与特征脸,神经网络方法,支持向量机,隐马尔可夫模型,Adaboost算法。
常用的 Haar 分类器方法,包含了 Adaboost 算法。分类器指的是对实物进行分类,聚类的过程。 OpenCV 也提供了 Haar 分类器方法。
-
分类:一般对已知物体类别总数的识别方式我们称之为分类,并且训练的数据是有标签的,比如已经明确指定了是人脸还是非人脸,这是一种有监督学习。
- 聚类:也存在可以处理类别总数不确定的方法或者训练的数据是没有标签的,这就是聚类,不需要学习阶段中关于物体类别的信息,是一种无监督学习。
Haar 分类器
常用的 Haar 分类器方法,包含了 Adaboost 算法。分类器指的是对实物进行分类,聚类的过程。 OpenCV 也提供了 Haar 分类器方法。 Haar分类器用到了Boosting算法中的AdaBoost算法,只是把AdaBoost算法训练出的强分类器进行了级联,并且在底层的特征提取中采用了高效率的矩形特征和积分图方法。
Haar分类器 = Haar-like特征 + 积分图方法 + AdaBoost +级联;
Haar分类器算法的要点如下:
- 使用Haar-like特征做检测。
- 使用积分图(Integral Image)对Haar-like特征求值进行加速。
- 使用AdaBoost算法训练区分人脸和非人脸的强分类器。
- 使用筛选式级联把强分类器级联到一起,提高准确率。
Haar-like 方法
Haar-like 特征主要分为:边缘特征、线性特征、中心特征和对角线特征,组合成特征模板。特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素和减去黑色矩形像素和。
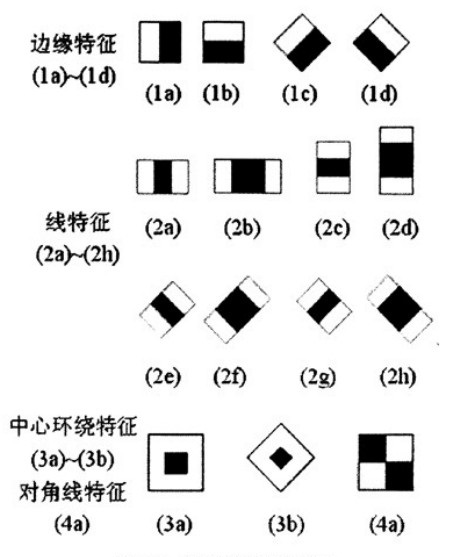
通过改变特征模板的大小和位置,可在图像子窗口中穷举出大量的特征。左图中的特征模板称为“特征原型”;特征原型在图像子窗口中扩展(平移伸缩)得到的特征称为“矩形特征”;矩形特征的值称为“特征值”。
矩形特征可位于图像任意位置,大小也可以任意改变,所以矩形特征值是矩形模版类别、矩形位置和矩形大小这三个因素的函数。故类别、大小和位置的变化,使得很小的检测窗口含有非常多的矩形特征。
对于图中的 1a, 1b和4a这类特征,特征数值计算公式为:v=Σ白-Σ黑,而对于2a来说,计算公式如下:v=Σ白-2*Σ黑;之所以将黑色区域像素和乘以2,是为了使两种矩形区域中像素数目一致。
Haar 特征数量的计算

以一个 24 × 24 的窗口为例,且使用左图中的特征模板,可能的特征数量是?
矩形的宽高比为 2:1 ,宽高可取的范围都为 24 ,那么所有可能的组合就为(高 × 宽): 1x2, 1x4, 1x6, 1x8, ..., 1x24, 2x2, 2x4, 2x6, 2x8, ..., 2x24, 3x2, 3x4, 3x6, ..., 一直到 24x24.
特征大小为2x1,在24x24的图像上,水平可滑动23步,垂直可滑动24步。当特征水平放大为41后,水平滑动步数为24-4+1=21步数。其步数随特征放大递减,python代码可表示为range(1,23+1,2),总共个数为sum(range(1,23+1,2))=144。同理垂直方向计算得到的特征总个数为sum(range(1,24+1,1))=300。整个的特征个数为144300 = 43200。

可以看到五种特征矩形的宽高比分别为:(a) 2:1,(b) 3:1, (c) 1:2, (d) 1:3,(e) 2:2. 那么每种类型的 特征值数量为:43200, 27600, 43200, 27600, 20736。总计为 160381 。
其中 W×H 表示图片的宽高,w×h 表示特征矩形的宽高,X=W/w,Y=H/h 表示在水平以及垂直方向的缩放系数。
积分图
在24*24像素大小的检测窗口内矩形特征数量可以达到16万个。这样就有两个问题需要解决了: (1)如何快速计算那么多的特征?---积分图大显神通; (2)哪些矩形特征才是对分类器分类最有效的?---如通过AdaBoost算法来训练
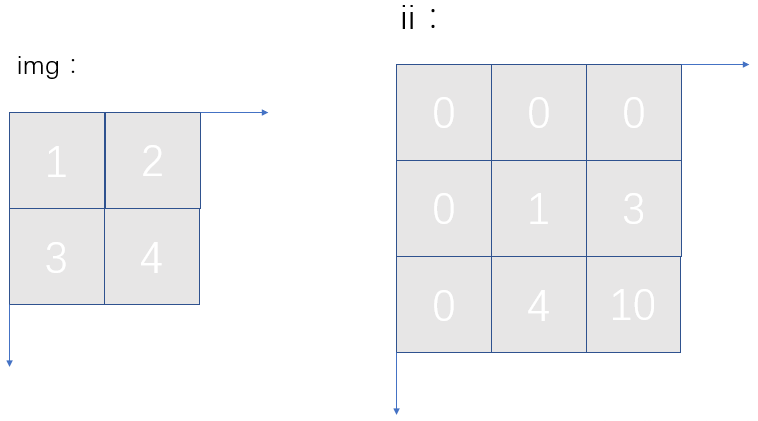
积分图主要的思想是将图像从起点开始到各个点所形成的矩形区域像素之和作为一个数组的元素保存在内存中,当要计算某个区域的像素和时可以直接索引数组的元素,不用重新计算这个区域的像素和,从而加快了计算(这有个相应的称呼,叫做动态规划算法)。积分图能够在多种尺度下,使用相同的时间(常数时间)来计算不同的特征,因此大大提高了检测速度。
积分图是一种能够描述全局信息的矩阵表示方法。积分图的构造方式是位置(i, j)处的值 ii(i, j) 是原图像(i, j)左上角方向所有像素 f(k, l) 的和:
积分图构建算法: 1、用 s(i, j) 表示行方向的累加和,初始化 s(i, −1) = 0; 2、使用 ii(i, j) 表示一个积分图像,初始化 ii(−1, j) = 0; 3、逐行扫描图像,递归计算每个像素(i, j)行方向的累加和 s(i, j) 和积分图像 ii(i, j) 的值: s(i, j) = s(i, j−1) + f(i, j) ii(i, j) = ii(i−1, j) + s(i, j) 4、扫描图像一遍,当到达图像右下角像素时,积分图像 ii 就构建好了。
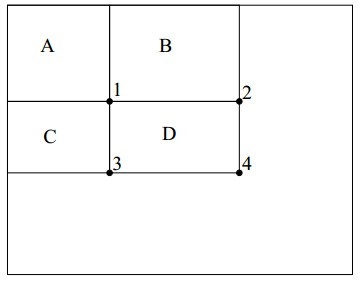
那么如何计算出 D 区域的积分图呢?可以看到 1 点的积分图为 A 矩形区域内的和即rectsum(A),同理可得出2、3、4点的积分图,即:
ii(1) = rectsum(A)
ii(2) = rectsum(A) + rectsum(B)
ii(3) = rectsum(A) + rectsum(C)
ii(4) = rectsum(A) + rectsum(B) + rectsum(C) + rectsum(D)
那么依此就可以算出 D 区域内的总和为 rectsum(D) = ii(4) + ii(1) - ii(2) - ii(3)。
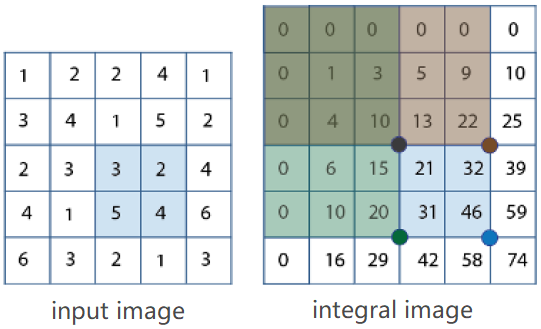
如果想求输入图像中蓝色区域内的像素值之和(3+2+5+4=14),只要根据和表积分图进行两次减法和一次减法即可:46+10-22-20=14。也就是右下角+左上角-右上角-左下角。
Adaboost
Adaboost 算法是基于 Boosting 算法,Boosting 算法涉及到两个重要的概念就是弱学习和强学习。 弱学习:就是指一个学习算法对一组概念的识别率只比随机识别好一点; 强学习:就是指一个学习算法对一组概率的识别率很高。
弱分类器和强分类器就是弱学习算法和强学习算法。弱学习算法是比较容易获得的,获得过程需要数量巨大的假设集合,这个假设集合是基于某些简单规则的组合和对样本集的性能评估而生成的,而强学习算法是不容易获得的。
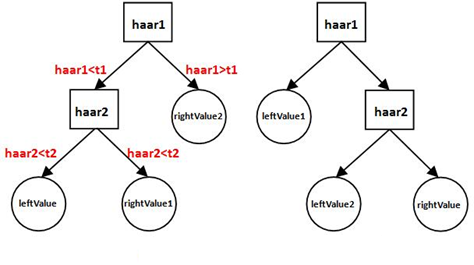
一个完整的弱分类器包含:Haar特征+ leftValue + rightValue + 弱分类器阈值(threshold),这些元素共同构成了弱分类器,缺一不可。haarcascade_frontalface_alt2.xml的弱分类器深度为2,包含了2种形式,如图。图中的左边形式包含2个Haar特征、1个leftValue、2个rightValue和2个弱分类器阈(t1和t2);右边形式包括2个Haar特征、2个leftValue、1个rightValue和2个弱分类器阈。
- 计算第一个Haar特征的特征值haar1,与第一个弱分类器阈值t1对比,当haar1<t1时,进入步骤2;当haar1>t1时,该弱分类器输出rightValue2并结束。
- 计算第二个Haar特征值haar2,与第二个弱分类器阈值t2对比,当haar2<t2时输出leftValue;当haar2>t2时输出rightValue1。
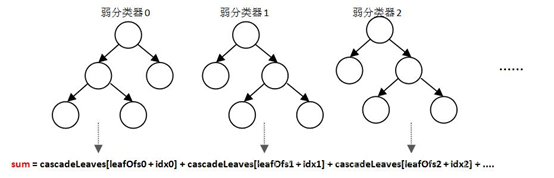
强分类器是由多个弱分类器“并列”构成,即强分类器中的弱分类器是两两相互独立的。在检测目标时,每个弱分类器独立运行并输出cascadeLeaves [leafOfs- idx]值,然后把当前强分类器中每一个弱分类器的输出值相加,即: sum += cascadeLeaves[leafOfs -idx]; 之后与本级强分类器的stageThreshold阈值对比,当且仅当结果sum>stageThreshold时,认为当前检测窗口通过了该级强分类器。当前检测窗口通过所有强分类器时,才被认为是一个检测目标。
强分类器与弱分类器结构不同,是一种类似于“并联”的结构。
在现实的人脸检测中,只靠一个强分类器还是难以保证检测的正确率,这个时候,需要一个豪华的阵容,训练出多个强分类器将它们强强联手,最终形成正确率很高的级联分类器这就是我们最终的目标Haar分类器。
级联分类模型是树状结构可以用下图表示:
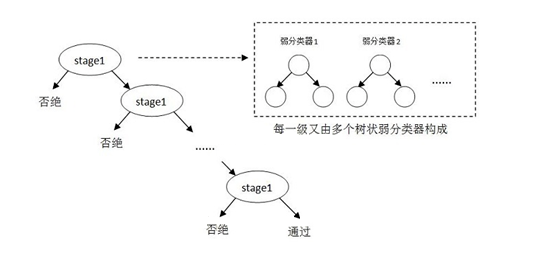
其中每一个stage都代表一级强分类器。当检测窗口通过所有的强分类器时才被认为是正样本,否则拒绝。实际上,不仅强分类器是树状结构,强分类器中的每一个弱分类器也是树状结构。每一个强分类器一旦发现检测到的目标为负样本,就不在继续调用下面的强分类器,减少了很多的检测时间。因为一幅图像中待检测的区域很多都是负样本,这样由级联分类器在分类器的初期就抛弃了很多负样本的复杂检测,所以级联分类器的速度是非常快的;只有正样本才会送到下一个强分类器进行再次检验,这样就保证了最后输出的正样本的伪正(false positive)的可能性非常低。
级联强分类器的策略是,将若干个强分类器由简单到复杂排列,希望经过训练使每个强分类器都有较高检测率,而误识率可以放低,比如几乎99%的人脸可以通过,但50%的非人脸也可以通过,这样如果有20个强分类器级联,那么他们的总识别率为0.99^20约等于98%,错误接受率也仅为0.5^20约等于0.0001%。这样的效果就可以满足现实的需要了。
AdaBoost训练出来的强分类器一般具有较小的误识率,但检测率并不很高,一般情况下,高检测率会导致高误识率,这是强分类阈值的划分导致的,要提高强分类器的检测率既要降低阈值,要降低强分类器的误识率就要提高阈值,这是个矛盾的事情。
增加分类器个数可以在提高强分类器检测率的同时降低误识率,所以级联分类器在训练时要考虑如下平衡,
- 弱分类器的个数和计算时间的平衡,
- 强分类器检测率和误识率之间的平衡。
遍历图像
检测窗口大小固定(例如alt2是20*20像素)的级联分类器如何遍历图像,以便找到在图像中大小不同、位置不同的目标?
- 为了找到图像中不同位置的目标,需要逐次移动检测窗口(随着检测窗口的移动,窗口中的Haar特征相应也随着窗口移动),这样就可以遍历到图像中的每一个位置;
- 为了检测到不同大小的目标,一般有两种做法:逐步缩小图像or逐步放大检测窗口。 缩小图像就是不改变搜索窗口的大小,而不断缩放图片,这种方法显然需要对每个缩放后的图片进行区域特征值的运算,效率不高。 放大检测窗口是把检测窗口长宽按照一定比例逐步放大,这时位于检测窗口内的Haar特征也会对应放大,然后检测。 一般来说,放大检测窗口相比运行速度更快。
OpenCV 人脸检测
OpenCV内部集成了人脸检测算法,并且OpenCV提供了训练好的人脸检测haar模型,使用xml保存。我们只需要简单的调用其中的类库就可以对照片或者视频进行人脸检测。
OpenCV自带的Haar特征检测,训练好的模型的存放网址为:https://github.com/opencv/opencv/tree/master/data/haarcascades
利用OpenCV的Python接口实现人脸检测的流程如下:
- 读取图片
- 将图片转换为灰度模式,便于人脸检测
- 利用Haar特征检测图片中的人脸
- 绘制人脸的矩形区域
- 显示人脸检测后的图片
cv.CascadeClassifier(filename) -> <CascadeClassifier object>
cv.CascadeClassifier.detectMultiScale(image[, scaleFactor[, minNeighbors[, flags[, minSize[, maxSize]]]]]) -> objectsminNeighbors : Parameter specifying how many neighbors each candidate rectangle should have to retain it.
minNeighbors = 0

minNeighbors = 1

minNeighbors = 3

参考:
https://zhuanlan.zhihu.com/p/38056144
https://blog.csdn.net/zouxy09/article/details/7929570
https://cloud.tencent.com/developer/article/1084469
https://my.oschina.net/u/4286379/blog/4257853
https://blog.csdn.net/zouxy09/article/details/7922923
https://fainke.com/blog/da5401e0.html
https://www.cnblogs.com/zyly/p/9410563.html
https://blog.csdn.net/playezio/article/details/80471000
https://www.cnblogs.com/jclian91/p/9667669.html
https://stackoverflow.com/questions/22249579/opencv-detectmultiscale-minneighbors-parameter
